개요
요즘 기계 학습(Machine Learning, ML)을 이용한 프로그램이나 앱이 많이 등장하고 있습니다. 기계 학습의 결과를 .Net framework C# 환경에서 연동하는 방법을 알아보도록 하겠습니다.
ONNX
ONNX 는 (Open Neural Network Exchange) 를 줄인 것으로 여러가지 학습 플랫폼의 결과를 서로 사용할 수 있게 하는 일종의 프레임워크 같은 개념입니다.
기계 학습의 결과를 ONNX 파일로 저장하는 방법은 이 글의 범위를 넘어가게 됩니다. 좋은 글이 많이 있으므로 그것을 참조하시면 됩니다.
이 글에서는 직접 기계학습으로 저장한 것이나 다른 곳에서 구한 ONNX 파일을 사용하는 것으로 하겠습니다.
Netron
직접 기계 학습의 결과를 저장했다면 어떤 값을 입력했고 출력 되는 값을 이미 알고 있습니다. 그러나 다른 곳에서 전달 받았거나 구한 파일만 있다면 그것을 정확히 알 수 없습니다. 이때 사용하는 프로그램이 Netron 입니다.
웹사이트에 방문하여 파일을 올리면 구조를 시각화해서 보여주므로 매우 편리합니다. 파일을 올리는 것이 꺼려지는 분들은 Github 에서 설치본을 받아 설치한 후 사용하시면 됩니다.
필자는 타이타닉 생존자 데이터를 가지고 기계 학습을 통해서 예측하는 모델로 export 한 파일을 사용하였습니다.
ONNX 파일을 Netron 으로 열어보면 다음과 같습니다.
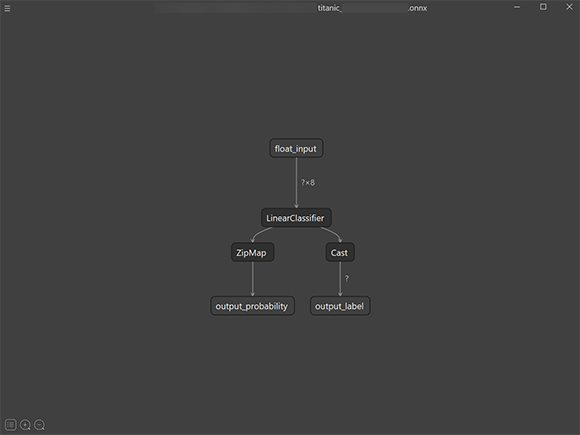
모델이 간단하여 복잡하지 않습니다. 기계 학습을 위해 입력한 값이 float 형으로 8개 이고 출력 값이 확률과 레이블(목표값)임을 알 수 있습니다.
C# 코드
위에 언급한 ONNX 파일을 이용하여 예측 값을 가져오는 코드는 다음과 같습니다.
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
...
string ONNX_MODEL_PATH = "D:\\yourPaht\\your.onnx";
InferenceSession session = new InferenceSession(ONNX_MODEL_PATH);
DenseTensor<float> denseTensor;
float[,] predictInput = new float[1, 8];
predictInput[0, 0] = 3f;
predictInput[0, 1] = 1f;
predictInput[0, 2] = 16.0f;
predictInput[0, 3] = 2f;
predictInput[0, 4] = 0f;
predictInput[0, 5] = 18.000f;
predictInput[0, 6] = 7f;
predictInput[0, 7] = 3f;
denseTensor = predictInput.ToTensor();
var inputMetaData = session.InputMetadata;
var outputMetaData = session.OutputMetadata;
var modelInput = new List<NamedOnnxValue>();
foreach (var name in inputMetaData.Keys)
{
modelInput.Add(NamedOnnxValue.CreateFromTensor<float>(name, denseTensor));
}
try
{
var results = session.Run(modelInput);
var inferenceResult = results.ToList()[0];
var inferenceResultValue = inferenceResult.Value;
var modelOutput = results.ToList()[0].AsTensor<long>().ToArray<long>()[0].ToString();
Console.WriteLine("Predict Survived : " + modelOutput.ToString());
Console.ReadLine();
}
catch (Exception error)
{
Console.WriteLine(error.Message);
Console.ReadLine();
}
9~28 행은 입력 값으로 8개의 항목을 입력하는 코드입니다.
32~39 행은 입력 데이터를 적용해서 그 결과를 출력하는 부분 입니다.
위 결과를 수행해 보면 다음과 같습니다(1이 생존).
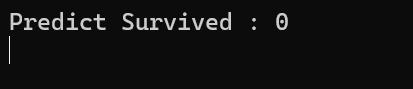
입력 값의 항목을 변경하면 예측한 값이 달라집니다.
이번 글에서는 ONNX 파일을 .Net framework C# 환경에서 사용하는 방법을 알아보았습니다.